Domeniul rețelelor neuronale este unul foarte activ la ora actuală, lucru oarecum surprinzător, ținând cont că unele idei au apărut în urmă cu 60 de ani. Doar în ultimii ani, acest domeniu a devenit cu adevărat atractiv, datorită plăcilor GPU care au permis o viteză de antrenare mult mai mare. Rețelele neuronale fac parte din spectrul larg al inteligenței artificiale, dar după cum veți vedea, o bună parte din conceptele prezentate aici se regăsesc și la alte clase de algoritmi.
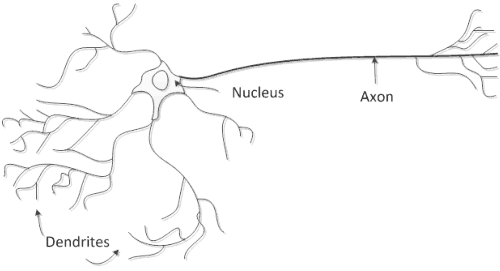
În biologie, neuronul este o celulă adaptată la recepționarea și transmiterea informației. Un număr suficient de mare de astfel de celule pot crea structuri de o complexitate deosebită, exemplul pertinent fiind creierul nostru. De aici a pornit ideea rețelelor neuronale artificiale(ANN). Deși sunt mult mai simple, ele oferă o serie de rezultate remarcabile, comparabile în unele cazuri cu cele obținute de oameni.
Warren McCulloch și Walter Pits au creat în anii ’40 prima abstractizare al acestui mecanism complex. La început, ei au privit acest neuron ca o funcție matematică. Deși este o abordare foarte simplistă, măcar oferă o primă abstractizare matematică a neuronului. Astfel:
Sinapsele pe care un neuron le făcea prin dendrite cu alți neuroni au devenit INTRĂRI;
Corpul neuronului a devenit un SUMATOR + o FUNCȚIE DE ACTIVARE(fc. de TRANSFER)
Axonul a devenit IEȘIREA
Pentru a surprinde caracteristici neliniare simple s-a introdus noțiunea de bias
Despre bias
Ca o paranteză, în română, bias s-ar traduce ca prejudecată (desi în tehnică, cuvântul predispoziție paremi-se că e mai sugestiv). Un exemplu mai plastic ar fi pareidolia – acea trăsătură a psihicului nostru ce ne face să vedem fețe umane…peste tot: vedem un craniu pe Lună, o față în spuma de cafea etc. De fapt, este predispoziția noastră de a găsi tipare în lucrurile pe care le observăm, chiar și acolo unde ele nu există.
Mai formal, înseamnă să ai un răspuns de bază la o anumită intrare. Să dau câteva exemple:
Electroniștii rar vorbesc de componenta constantă a unui semnal(ei rezolvă de la început asta cu niște condensatoare). Pentru aceștia e mai importantă partea ce variază tot timpul. De aceea, în calcule, se scade componenta pasivă și rămânem cu o serie de sinusoide(facem transformata Fourier, mergem în domeniul frecvență etc.).
În statistică se lucrează adesea cu scoruri z care se obțin prin scăderea mediei si împărțirea rezultatului cu deviația standard (din nou, s-a eliminat componenta constantă). Am discutat în articolul Importanța scalării trăsăturilor despre asta pe larg.
O celulă de memorie DRAM (memorie volatilă, cu condensator) nu poate să tragă la 0 sau la 1 logic linia de citire atunci când se citește un bit din aceasta ci numai modifică puțin valoarea medie 0.5 … un soi de +0.5 sau –0.5. Motivul este dimensiunea redusă a condensatorului – atât de redusă, încât nu poate modifica decât puțin potențialul liniei de citire.
Din exemplele de mai sus putem observa că la un nivel mai abstract, doar variațiile dintr-un sistem sunt purtătoare de informație utilă. De aceea, rețelele neuronale trebuie să învețe, în primul rând, variațiile. Dar nu putem omite componenta constantă. De aceea, fiecare neuron va avea o intrare dedicată „învățării” acestei componente constante, pe care tradițional o vom numi bias și o vom nota cu b. În fine, se poate omite această intrare, dar e doar un tertip la nivelul notației. Tot timpul, neuronul va avea această intrare dedicată învățării valorii de bază(componenta constantă). Pentru a vedea rolul lui b, mergi la anexa 1, unde este un exemplu foarte simplu al funcției boolene AND folosind o rețea neuronală cu perceptroni (neuroni cu ieșire binară).
2. Ce este o rețea neuronală?
Structural, atunci când avem o serie neuroni interconectați putem vorbi de o rețea neuronală. Este o definiție inspirată din biologie, din analogia cu creierul uman unde neuronii, deși pot avea funcții foarte specifice, aparent formează un tot unitar.
Funcțional, am putea defini o rețea neuronală, ca acel sistem format dintr-un număr variabil (adesea mare) de elemente interconectate (modelul matematic al neuronului) ce conlucrează pentru rezolvarea unei probleme. Poate cea mai importantă trăsătură a acestor rețele este că pot fi îmbunătățite prin învățare. Mai formal, rețeaua poate să își modifice o ipoteză inițială într-o manieră care să îi permită să explice mai bine caracterul unor date. Nu vreau să intru încă în detalii, dar ca și în viața reală, dacă o ipoteză explică foarte bine un fenomen nu înseamnă neapărat că ea este și adevărată. Modelul heliocentric explica multe, dar acum știm ce departe era de adevăr. Toate sistemele care pot să învețe suferă de această problemă și o întreagă arie de cercetare este dedicată rezolvării acestei probleme. Acest fenomen poartă numele de overfitting (supra-ajustare).
La prima vedere, uitându-ne la structura simplă a neuronului lui McCulloch, am putea să credem că aplicațiile ce pot fi tratate cu aceste rețele ori nu sunt multe, ori sunt foarte simple, dar ne-am înșela în ambele situații. Acest aspect mi se pare foarte interesant, fiindcă aceste rețele manifestă ceea ce mulți ar numi emergență (precum Conway’s game of life).
Printre cele mai importante aplicații, se numără:
Procesarea limbajului natural (NLP)
Recunoașterea imaginilor și obiectelor
Jocuri de inteligență artificială
Predicții financiare și economice
Identificarea fraudelor
Sisteme de recomandare
Controlul robotilor și automatizări industriale
Analiza de date și minerit de date
Procesarea semnalelor și a imaginiilor medicale
Marketing și publicitate personalizată.
3. Arhitectura rețelelor neuronale
Voi încerca să nu intru în detalii și voi pune accent pe intuiție în detrimentul specificității matematice. De asemenea, cred că adesea, lumea trece cu vederea aceste „detalii” și astfel se pierde înțelegerea per ansamblu a sistemului. Chiar nu îmi doresc să popularizez ideea că „Machine Learning e simplu…îi dai niște date, run și gata” – acesta e doar efectul a 70 de ani de muncă coagulați într-o serie de librării care ne permit să scriem 20 de linii de cod și să recunoaștem câte degețele sunt în vreo poză(acesta e exemplul istoric). Faptul că sunt necesare librării relativ mari pentru lucruri așa simple are o serie de implicații filozofice…surprinse bine de paradoxul lui Moravec.
3.1 Tipuri de rețele
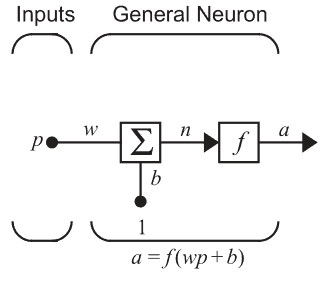
Neuron cu o singură intrare
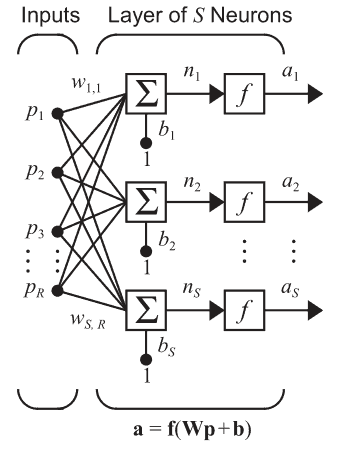
Rețea cu un singur nivel de neuroni. Aici p este un vector, iar W este o matrice cu S linii și R coloane
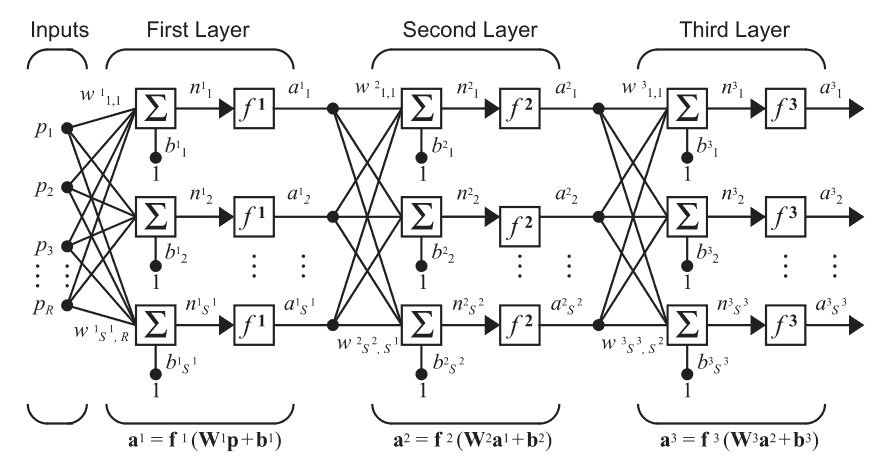
Observăm că deși poate părea complicat, formula finală e doar un efect combinat al rețelelor cu un singur nivel extins la mai multe.
3.2. Funcții de activare
Plecând de la ideea că un neuron poate fi reprezentat de un sumator și o funcție, atunci o rețea neuronală va deveni o mulțime de funcții interconectate. Este important totuși să definim tipul de funcții folosite.
Aceste funcții reprezintă filtrele prin care va trece informația. Vrem totuși un set de funcții cu proprietăți specifice, fiindcă de ele depinde cum trebuie să modificăm ponderile, modificarea acestora reprezentând învățarea rețelei neuronale. Modificarea funcțiilor implică să le variem în timp, deci să ne jucăm și cu derivatele lor. Deși ruptă puțin din context, ideea învățării rețelelor neuronale prin metoda gradientului chiar este o metodă consistentă și este folosită adesea la antrenare.
Voi detalia acum două funcții de activare foarte populare, cea mai importantă fiind sigmoida. Înainte de a vorbi de sigmoidă, voi încerca să surprind modul în care, istoric, această funcție a luat naștere, ca o generalizare naturală a unei funcții mult mai simple și anume funcția lui Heaveside(folosită la perceptroni). Vom vedea care sunt limitările ei, pentru a remarca apoi, ce fain se astupă acel gol cu sigmoida.
Să facem o paranteză și să ne gândim la populații…așa s-a gândit și un tip pe nume Pierre François Verhulst care a vrut să găsească modelul matematic la aceste creșteri. La ce s-a gândit e chiar interesant…
Să zicem c-avem o populație cu K membri. Copiii care apar în această populație sigur depind de numărul de indivizi din ea(logic nu-i așa). Cu cât K e mai mare…mai mulți copii și vice versa. Dar cine sunt copiii? Dacă presupunem că nimeni nu moare atunci copiii reprezintă chiar variația populației K. Deci:
Deși destul de bun, acest model nu prea reflectă realitatea. Populația în acest caz ar crește imediat spre valori foarte mari, iar asta nu prea pare să fie în concordanță cu realitățile. Să schimbăm puțin problema și să ne gândim altfel…să zicem că populația noastră va fi P, iar populația maximă ce poate fi suportată de mediu este K(ca și cum am zice că pe Pământ nu pot să trăiască mai mult de 10 miliarde de oameni și basta). Pare o idee simplă și chiar este…da cum rămâne cu variația populației și implicit cu copiii? Păi, intuitiv, când populația e mică…numărul de copii contează foarte mult și ne așteptam ca populația să crească semnificativ(o rata mare de creștere). Pe măsură ce ne-apropiem de limita mediului…populația ar trebui să nu mai poată crește, adică rata de creștere a populației să scadă, iar populația să rămână la valoarea maximă(10 miliarde în cazul nostru). Matematic:
Astfel de funcții(se mai numesc funcții logistice) îs tare bune și pentru rețele neuronale fiindcă mărginesc rezultatele – le pun într-o gamă cât de cât controlabilă de valori.
După cum spuneam, să vedem de ce funcția lui Heaveside(funcția treapta) de mai jos poate avea anumite limitări, în special în problemele cu un anumit grad de incertitudine (cum sunt majoritatea de altfel).
Exemplul constă într-o rețea neuronală capabilă să recunoască cifre. Să presupunem că folosim un MLP, iar la un moment dat ne vom dori să recunoaștem cifra 6. Rețeaua cu perceptroni simpli va învăța modificând ponderile până când răspunsul rețelei e cel așteptat – 6. Problema va fi cu celelalte numere, rețeaua probabil fiind destabilizată. Astfel de rețele MLP sunt rigide, tocmai datorită modului de funcționare a perceptronului. Nefiind decât 2 stări distincte, trecerea de la 0 la 1 s-a făcut la o schimbare probabil mică a ponderilor. Din acest motiv se folosesc neuronii sigmozi, ce au sigmoida ca funcție de activare. Ea poate acoperi întreg intervalul [0,1], iar astfel se asigură o relație reciprocă între ponderi și intrări – variații mici la ponderi vor induce variații mici la ieșiri.
Să fim acum puțin mai specifici. Vom dezvolta puțin rezultatul obținut în căsuța matematică, cel cu distribuția populațiilor.
Se poate observa din graficul funcției sigmoide de mai sus că am putea s-o folosim cu succes pentru a defini o probabilitate. Asta, fiindca funcția e mărginită între 0 și 1, exact ca și în cazul unei probabilități. Pentru a vedea mai bine, să luăm următoarea poză:
Am vrea o funcție care să ne spună, pe axa gradientului de culoare, cu ce probabilitate avem o anumită culoare. Deci suntem precum un calculator, orbi, dar mergem pe acea axă și vrem ca la fiecare pas ce-l facem să zicem, cu o anumită probabilitate, culoarea. Funcția sigmoidă e numai bună pentru asta. Dacă luăm acei pași și îi punem pe funcția noastră, am obține ceva de genul:
Putea fi și invers, roșu la 1 și albastru la 0, dar așa am vrut eu. Adesea, lumea preferă totuși să zică următoarea chestie: Care e probabilitatea ca acest punct să fie de culoare roșie? (sau albastră). Ce e important aici e că menționez o singură culoare. În poza de mai sus, sunt cumva ambele acolo, pe același grafic. Vreau să le separ în două grafice ( o să înțelegem imediat de ce). Soluția e simplă: facem simetricul funcției de mai sus, față de y, și obținem probabilitatea pentru cealaltă clasă.
Se merită să scriem clasificatorul binar cu două funcții, fiindcă putem intui cum să generalizăm pentru mai multe clase. Această nouă funcție se va numi softmax, iar în cazul particular cu două clase, softmax se va reduce la sigmoid. Funcția softmax arată astfel:
Vedem avantajul scrierii de mai sus…acum putem lucra cu mai multe clase, deci mai multe culori…gata cu clasificatorii binari.
Funcția ar avea acum ieșiri de genul.
Ba mai mult de atât, fiind la mijloc niște exponențiale, pe măsură ce rețeaua devine mai bună o clasă va deveni din ce în ce în ce mai probabilă, celelalte fiind exponențial mai mici. „Efectul” învățării seamănă mult cu efectul micsorării deviației standard din distribuția lui Gauss – clopotul devine mai ascuțit, un set tot mai mare de puncte din jurul mediei ajungând să fie apropiat de aceasta => crește precizia.
4. Tipuri de rețele
Taxonomiile din toate cărțile de specialitate se fac după tipul conexiunilor sau după direcția semnalului în rețea.
Tipul conexiunilor făcute de neuroni
Rețele neuronale feed-forward: sunt cel mai simplu tip de rețele neuronale, în care informația se propaga doar înainte, de la intrare la ieșire, fără alte conexiuni înapoi.
Rețele neuronale recurente (RNN): sunt rețele neuronale în care informația poate circula în ambele sensuri, atât înainte cât și înapoi. Acestea sunt utilizate pentru procesarea secvențelor de date, cum ar fi textul sau sunetul.
Rețele neuronale cu auto-reglare (self-supervised): sunt rețele neuronale care învață prin intermediul reprezentărilor propriilor date, fără a fi nevoie de etichete sau de un set de date de antrenament.
Rețele neuronale convoluționale (CNN): sunt rețele neuronale specializate pentru recunoașterea obiectelor în imagini, utilizând filtre pentru a detecta caracteristici specifice.
Rețele neuronale adânci (DNN): sunt rețele neuronale cu mai multe straturi ascunse, care pot fi utilizate pentru diverse aplicații, cum ar fi procesarea limbajului natural, recunoașterea imaginilor și controlul roboților.
Rețele neuronale ce utilizează „atenția”: utilizat pentru procesarea limbajului natural, acest tip de rețea neuronală se concentrează pe anumite cuvinte sau fraze relevante din textul de intrare.
Direcția semnalului
Rețele feedforward – care sunt rețele multilayer unde informația „curge” într-o singură direcție(în teoria sistemelor, analogia ar fi sisteme fără reacție).
Rețele feedback – unde există reacție, adică legături dintr-un strat superior la altele anterioare.
5. Modalități de învățare a rețelelor neuronale
Învăţarea automată, unul din sub-domeniile de bază ale Inteligenţei Artificiale, se preocupă cu dezvoltarea de algoritmi şi metode ce permit unui sistem informatic să înveţe date, reguli, chiar algoritmi.
Privite în ansamblu, mecanismele de învățare a rețelelor neuronale se pot împărți în două clase:
Supravegheate(Supervised) – Fiindcă vorbim de un tip de învăţare inductivă ce pleacă de la un set de exemple de instanţe ale problemei şi formează o funcţie de evaluare (şablon) care să permită clasificarea (rezolvarea) unor instanţe noi. Învăţarea este supervizată în sensul că setul de exemple este dat împreună cu clasificarea lor corectă.
Nesupravegheate(Unsupervised) – În acest caz setul de antrenare conține doar date de intrare
Exemplu: gruparea datelor în categorii în funcție de similitudinea dintre ele
Se bazează pe proprietățile statistice ale datelor
Nu se bazează pe conceptul de funcție de eroare ci pe cel de calitate a modelului extras din date, care trebuie maximizat prin procesul de antrenare.
Înțelegem arhitectura neuronului, am vorbit despre funcții de activare, dar nu vedem cum putem obține din tot acest ansamblu rezultate concrete. Aici intervine cel mai important proces al întregului mecanism – metoda de învățare. În timp, veți realiza că aproape toată complexitatea din spatele rețelelor neuronale rezidă aici, iar tratarea riguroasă ar ieși cu mult din sfera acestui articol.
Totuși voi aminti de o tehnică mai generală, folosită cu predilecție în regresii. În statistică, prin regresie înțelegem procedeul prin care se pun în legătură variabilele dintr-un spațiu. În practică, legătură între variabile ar putea fi destul de ascunsă. TU ești cel care decizi gradul de legătură. Dacă te chinui multă vreme e posibil să găsești o legătură între orice tip de variabile, chiar și cele care logic sunt necorelate. Problema este delicată fiindcă de fapt faci overfitting, adică ai găsit o legătură, dar care nu poate generaliza deloc.
Doi iepuri dintr-o lovitură
Voi încerca să împusc doi iepuri dintr-o lovitură, prezentând același concept cu o minoră schimbare pentru a vedea cum putem face regresii, cât și clasificări.
5.1.1. Regresia liniară și funcția de cost
Rețelele neuronale pot fi privite ca un mecanism general prin care putem aproxima funcții, de orice fel ar fi ele. E natural deci să încep cu cele mai simple funcții, cele liniare.
În imaginea de mai jos vedem o dependență liniară între două variabile – nu știu în ce context, dar nu-i important…e o dependență liniară. Ne-am dori un algoritm care să găsească acea linie albastră. Probabil nu va putea s-o nimerească din prima(dacă nu mă crezi leagă-te la ochi și încearcă). Nu am zis-o chiar ironic, fiindcă același lucru o să-l facă algoritmul nostru, la primul PAS.
În esență vrem să găsim (w^*,b^*) astfel încât y = w^*x + b^* să fie cea mai bună linie pentru punctele de mai sus.
Pasul 1 constă, așa cum am spus, în alegerea a doi parametri aleatori, w_0 și b_0. Din comoditate, să zicem că am ales (0.1, 25). Ce-am obținut? Linia cea verde…
Regresia liniara
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(5)
x = np.arange(0,100)
y = 0.5 + 1/2 * x + np.random.normal(0, 4, 100)
plt.plot(x, y, "o")
plt.plot(np.arange(0,100), eval('1/2 + 1/2*x'), "b")
plt.plot(np.arange(0,100), eval('25 + 0.1 * x'), "g")
plt.show()
Începem să vedem că am avea nevoie de un algoritm care să modifice la fiecare pas cele două valori astfel încât după câteva iterații linia verde să fie, ideal, suprapusă peste cea albastră. Ne trebuie un mecanism prin care să penalizăm algoritmul dacă e departe de parametrii ideali…să înțeleagă că erorile au în viață un COST. Ce cost ar fi aici bun?
O soluție rezonabilă este să măsurăm distanța de la valoarea așteptată până la cea obținută. Dacă numărul de puncte rămâne constant, am putea liniștiți să găsim un cost mediu fiindcă nu ne afectează. Putem deci să definim un C:
z(x_i,w,b) = wx_i + b – are treabă cu modelul generat de algoritmul nostru, adică Y-ul de pe linia verde corespunzator lui x_i. Valoarea așteptată e punctul albastru care s-a găsit la acel x_i, ce corespunde lui y_i.
Trebuie să găsim un mecanism prin care să minimizăm acest C. El este o funcție care depinde de 2 parametri reali, deci este o pătură. Problema se reduce la a găsi minimul. Din liceu, știm că locul în care derivatele unei funcții continue se anulează sunt punctele de extrem (de maxim sau de minim). Aici știm sigur că sunt de minim, fiindcă funcția e strict mai mare ca 0, deci are ca minim pe 0. Ne folosim atunci de gradient și vom merge împotriva sensului său de creștere.
\eta – reprezintă o rată de învățare ce dictează cât de repede mergem spre minim. Dacă e prea mare poate vom țopăi în jurul minimului, iar dacă e prea mică durează mult să ajungem la el. Mai rău de atât, în absența unei rate de învățare adecvate am putea rămâne blocați într-un minim local.
Actualizând parametrii w si b după regulile de mai sus, o să vedem că după câteva iterații cum linia verde se va apropia de cea albastră.
5.1.2. Clasificatorul liniar (perceptronul)
Mai sus am discutat de problema regresiei liniare. Vom vedea cum, făcând o modificare foarte subtilă putem să ne creăm un clasificator liniar. Trebuie o modificare simplă la modelul nostru prin introducerea unui nou element și anume funcția de activare. Pentru a înțelege rostul ei să ne uităm la imaginea de mai jos.
Clasificatorul liniar
Spre deosebire de exemplul cu regresia liniara, unde în funcția de cost adunam diferențele de la rezultatul generat până la cel așteptat, aici trebuie să cuantificăm faptul că linia probabil nu clasifică datele cunoscute de antrenament corect. Linia model(cea punctată), vedem că are următoarea proprietate:
g(x)=\left\{\begin{array}{ll}\;1, \;x \geq 0 \\ -1, x < 0\end{array}\right.
Combinând (1) și (2) cu funcția de activare g, putem folosi din nou funcția de cost C, exact ca și la regresia liniară, numai că acum vom avea:
C = \frac{1}{2n}\sum\limits_{i=0}^n(g(z) - a_i)^2
Aici a_i poate fi doar \pm 1 și reprezintă clasa reala a instanței din setul de training.
Mai am o singură remarcă: Cele două metode pe care le-ați putut vedea în acțiune mai sus folosesc în ambele cazuri un set de date cu valori cunoscute, adică un set de training. De aceea, ele fac parte din clasa de algoritmi supravegheați (supervised learning).
Pentru cei dornici să învețe mai multe, vă recomand să urmăriți secțiunea cu referințe, de la finalul acestui articol.
5.1.3. Învățarea competitivă
Învăţarea competitivă se bazează pe un proces concurenţial între neuronii din stratul de ieşire, existând un neuron „câştigător”, în detrimentul celorlalţi neuroni. Dacă în ceilalţi algoritmi de învăţare prezentaţi până acum, toţi neuronii din stratul de ieşire puteau genera valori de ieşire mai mari sau mai mici, în algoritmul de învăţare competitivă, doar neuronul de ieşire „câştigător” este activ (generează o valoare), ceilalţi neuroni de ieşire devenind inactivi (generează valoarea zero).
Date initiale negrupate
Formarea centroizilor prin învățare nesupravegheată
Să luăm imaginea de mai sus. Vom presupune, din varii motive, care țin de specificitatea problemei, că trebuie să clasificăm datele în 4 clase distincte. Vom avea o rețea neuronală generală, care poate avea foarte multe intrări (chiar în poza noastră e simplu că ar fi două numere, pentru cele două coordonate de pe plan), dar știm sigur că are doar 4 ieșiri. Comportamentul dorit al rețelei va fi, ca după antrenare, la o combinație de intrări să obținem la ieșire o singură clasă, iar restul 0. Spunem că acest comportament este competitiv, fiindcă doar o clasă poate fi câștigătoare => va fi o rețea cu perceptroni (unii zic perceptroni la neuronii sigmoizi, eu zic la cei cu funcția treaptă).
La finalul procesului de învățare vedem de fapt și ce a făcut rețeaua: a adus modificări la ponderile rețelei, până când acestea au clasificat corect toate datele de intrare. Cum știm câte modificări ar trebui să facem la acele ponderi? Până când funcția de cost ajunge la o valoarea mai mică decât pragul definit de noi, $latex epsilon $ să zicem.
Deci matematic:
ponderea j a neuronului i, adică w_{ij} se actualizează iterativ astfel: w^{k+1}_{ij} = w^{k}_{ij} + \Delta w^{k}_{ij}. \eta este un factor de învățare, de care depinde acuratețea învățării. Un factor \eta mare implică o acuratețe mai scăzută, dar viteză foarte mare și vice-versa. Deci variația va fi de forma:
Rețelele neuronale pot fi utilizate cu succes și în contextul învățării nesupravegheate. Un exemplu popular este harta cu auto-organizare sau SOM(Self Organizing Map sau Kohonen Map).
Înainte de a discuta de hărți Kohonen vă invit să ne gândim la următorul joc:
Ghicește culoarea bilei fără s-o vezi
Să ne imaginăm c-avem o masă pe care sunt împrăștiate biluțe de diferite culori. Ne întrebăm acum…dacă nu am vedea culorile, am putea determina culoarea unei bile într-o anumită poziție? Să fac problema mai simplă și să zic că avem 3 culori. Deci, dându-se (x,y,z) am putea spune care este c_i\in\{c_1, c_2, c_3\}?
Răspunsul e că la modul general NU. De exemplu, dacă culorile ar fi alese aleator pentru o anumită distribuție de biluțe pe masă, atunci de fapt nu există vreo regulă după care să ne ghidăm. Tot ce-am putea face în această situație ar fi să memorăm acea configurație.
Dar dacă nu ar fi alese aleator? Din păcate, tot NU. Și de-ar fi grupate foarte frumos în grupuri cu biluțe de aceeași culoare tot nu am putea spune ce culoare are de fapt grupul, fiindcă la urma urmei e limpede că ar trebui să ne uităm la grup pentru a fi cerți cu privire la culoarea acestuia.
Ce joc greu…am zice că nu putem face ceva în privința culorilor. Dar PUTEM! De exemplu, dacă suntem într-o situație nealeatoare, putem să estimăm câte culori distincte se află pe tablă pe baza structurii topologice induse de distribuția biluțelor. Deci rămânem cu c_1, c_2, c_3, atâta doar că nu putem spune ce reprezintă fiecare.
Treaba asta cu ce reprezintă fiecare e problema oricărui algoritm nesupravegheat. E ca și cum ai încerca să înveți o limbă străină numai din auzite…e incredibil că am facut cu toții asta când ne-am născut…Moravec, Moravec ce ne faci tu nouă!
Să vedem într-un exemplu totuși ce-i cu rețelele Kohonen. Nu vom implementa aici de la 0 o astfel de rețea. Voi folosi pachetul python minisom.
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from minisom import MiniSom
%matplotlib inline
def label_mvn(label, mean, cov, size): # multivariate gaussian
assert(isinstance(label, int))
gaussian = np.random.multivariate_normal(mean, cov, size)
return gaussian, np.array([label] * len(gaussian))
def labeled_normals(means, covs, default_size=100):
""" Un wrapper simplu peste label multivariate normal
pentru a construi rapid distributii de test"""
i = 0 # default class
dists, labels = [], []
for mean, cov in zip(means, covs):
label_dist = label_mvn(i, mean, cov, default_size)
dists.append(label_dist[0])
labels.append(label_dist[1])
i += 1
return dists, labels
def plot_dists(dists, marker='o'):
if len(dists)>5:
return 0
for i, dist in enumerate(dists):
plt.plot(dist[:, 0], dist[:, 1], 'C'+str(i)+marker)
means = [
[0, 5],
[6, 15],
[10, 1]
]
covs = [
[[0.4,0], [0, 4]],
[[2, 2], [0, 1]],
[[2, -1], [1.2, 1]]
]
labeled_dists = labeled_normals(means, covs)
dists, labels = labeled_dists[0], labeled_dists[1]
# Afisare distributii originale
plot_dists(dists)
data = np.concatenate(dists)
data = np.apply_along_axis(lambda x: x/np.linalg.norm(x), 1, data)
num = np.concatenate(labels)
width, height = 20, 20
dimensions = 2
som = MiniSom(
width, height, dimensions, sigma=3, learning_rate=1,
neighborhood_function='gaussian', random_seed=20
)
som.pca_weights_init(data)
som.train_random(data, 1000)
plt.figure(figsize=(width, height))
plt.pcolor(som.distance_map().T, cmap='bone_r')
markers = ['o', 's', 'D']
colors = ['C0', 'C1', 'C2']
for x, t in zip(data, num):
w = som.winner(x) # getting the winner
# place a marker on the winning position for the sample xx
plt.plot(
w[0]+.5, w[1]+.5, markers[t], markerfacecolor='None',
markeredgecolor=colors[t], markersize=12, markeredgewidth=2
)
plt.show()
plt.figure(figsize=(width, height))
wmap = {}
im = 0
for x, t in zip(data, num): # scatterplot
w = som.winner(x)
wmap[w] = im
plt. text(w[0]+.5, w[1]+.5, str(t),
color=plt.cm.rainbow(t / 10.), fontdict={'weight': 'bold', 'size': 18})
im = im + 1
plt.axis([0, som.get_weights().shape[0], 0, som.get_weights().shape[1]])
plt.show()
Rulând codul de mai sus vom obține:
Distribuția originală a datelor
Harta de distanță afișată sub forma de culoare
Etichetele cele mai probabile pe harta Kohonen
Cititorii atenți vor observa clasa cu numărul 0, care a fost aparent inversată cu clasa 1. Motivul se datorează modului de instanțiere a ponderilor, folosindu-se PCA. PCA e un topic destul de specific și va fi subiectul altui articol.
6. Modalități de îmbunătățire a învățării
6.1. Entropia încrucișată
Entropia încrucișată apare în contextul învățării rețelelor neuronale. Atunci când vorbim de învățare supravegheată, învățarea se rezumă la modificarea ponderilor și bias-urilor atașate neuronilor pentru ca întreaga rețea să mapeze rezultatele dorite. Entropia încrucișată s-a dezvoltat pornindu-se de la optimizarea funcției de cost prin metoda gradientului, atunci când s-au văzut primele limitări a acesteia.
Unde \sigma este sigmoida, iar z este intrarea ponderata, \sum_{k} w^L_{kj} a^{L-1}_k + b^L_j
Din ecuațiile de mai sus, se poate intui problema care a dat naștere entropiei încrucișate. Funcția \sigma(z) este sigmoida, iar această funcție variază foarte puțin în afara intervalului [-1,1]. Acest lucru implică că și derivata va tinde spre 0 când eroarea este mare, făcând învățarea mult mai grea.
Pentru a rezolva această problemă, va trebui introdusă o funcție de cost diferită, care să nu țină cont de comportamentul sigmoidei, pentru a facilita învățarea rapidă, chiar și atunci când variația sigmoidei este foarte mică. Intuitiv, ne-am putea întreba dacă există o astfel de funcție. În acest caz, am putea transforma ecuațiile de mai sus în:
Vedem că o condiție suficientă pentru ca ecuațiile de mai sus să fie satisfăcute este:
\max(w_1, w_2) < |b| \leq |w_1|+|w_2|
O asemenea condiție are o infinitate de soluții, iar în funcție de valoarea inițială a ponderilor w_1, w_2 avem o infinitate de bias-uri (ex. (2, 3, -4), (0.5, 0.5, -0.9), (10, 12, -13) etc.)
Gândire profundă, subiect de mare viitor! Pe saitul tău am petrecut mult timp în această dimineață, mulțumită lui Google. Am urmărit recent o emisiune privind inteligența artificială și au început să mă intereseze rețelele neuronale, așa că detaliile profunde pe care le scrii mă ajută mult, orientându-mi cercetarea în Fizică.
Ca o sugestie, îți recomand să studiezi teorema lui Bilinski, de recurență a triedrelor Frenet. Presimt că ar putea aduce mecanisme noi de optimizare a învățării automate.



{kind=link}
{kind=link}










Super articolul
Vă mulțumesc foarte mult.
Felicitari ! Foarte interesant articolul !
Multumesc!
Felicitari! Foarte bun articolul!
Bravo!! Foarte bun articolul.
Gândire profundă, subiect de mare viitor! Pe saitul tău am petrecut mult timp în această dimineață, mulțumită lui Google. Am urmărit recent o emisiune privind inteligența artificială și au început să mă intereseze rețelele neuronale, așa că detaliile profunde pe care le scrii mă ajută mult, orientându-mi cercetarea în Fizică.
Ca o sugestie, îți recomand să studiezi teorema lui Bilinski, de recurență a triedrelor Frenet. Presimt că ar putea aduce mecanisme noi de optimizare a învățării automate.